
La tech expliquée au personnes non-techniques: Comprendre l'ingénierie le jargon et comment les équipes fonctionnent facilement.

Je vais rédiger une série d’articles de blog pour aider les personnes non techniques à mieux comprendre ce qu’implique le monde de la tech.
Ces articles s’adressent à vous si vous envisagez une carrière dans le management tech, si vous souhaitez comprendre ce que fait votre équipe d’ingénierie, ou si vous êtes en transition vers un poste qui nécessite de mieux connaître la tech.
Je ne vais pas vous apprendre à coder ; car dans 99 % des cas, l’ingénierie ne consiste pas à écrire du code, mais à réfléchir à des systèmes et à les gérer ensemble. Pensez à un orchestre : la partition est le code, les musiciens sont les systèmes, et le chef d’orchestre représente le rôle de l’ingénieur.
Une remarque importante : les ingénieurs adorent l’humour; les memes sont devenus une vraie culture dans ces environnements. Vous devrez vous y adapter, et j’espère que vous les comprendrez mieux après avoir lu ces articles. – Je suis aussi un ingénieur, vous n’y échapperez pas.
Autre remarque importante; beaucoup de notions ne sont pas traduites, car les ingénieurs travaillent presque exclusivement en anglais. C’est plus simple pour communiquer, et vous avez accès à beaucoup plus d’aide (l’anglais est international). Les ingénieurs trouvent la majorité de leurs informations pour leur travail sur internet, donc en anglais. De manière générale c’est aussi un mécanisme automatique pour les ingénieurs, si on a une question, la première chose que l’on fait c’est de regarder sur internet pour une solution (les ingénieurs partagent aussi beaucoup de leur expérience), c’est un métier où on peut être autodidacte.
Ce blog est la première partie et va se concentrer sur la “boucle d’ingénierie”, les outils qui sont utilisés pour travailler et le jargon le plus important à savoir.
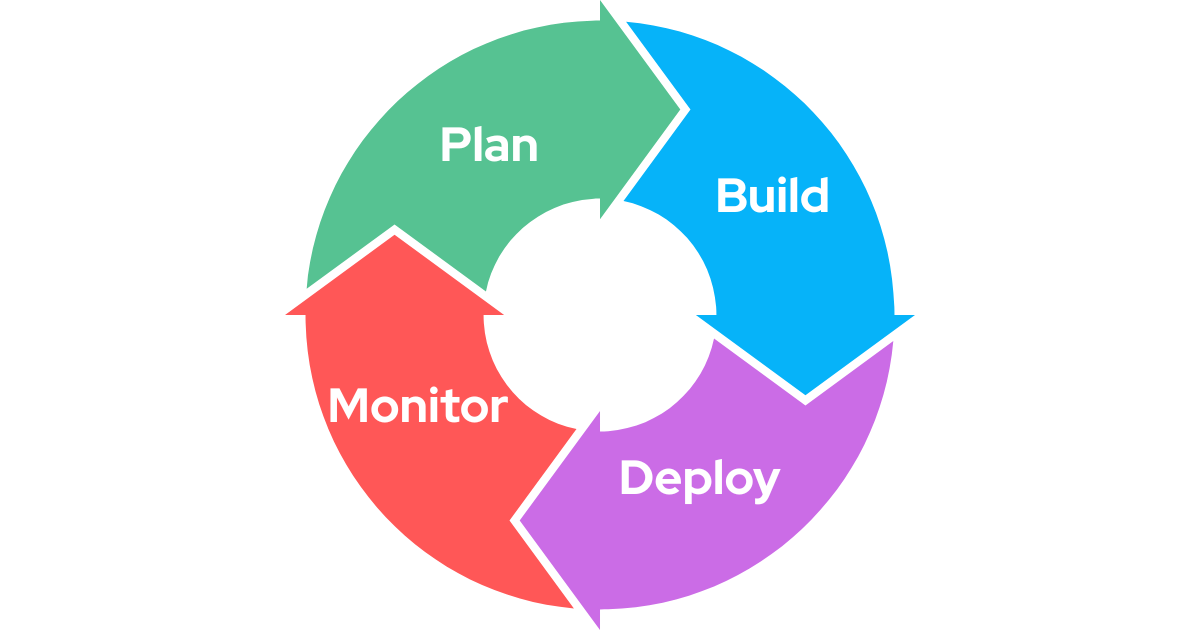
La boucle
L’ingénierie est une boucle qui peut se diviser en quatre étapes : Planifier, Construire, Déployer, Surveiller. Chacune de ces étapes dispose de ses propres outils pour vous aider dans votre travail.
Il existe de nombreuses façons d’exécuter cette boucle. À mon avis, trop de gens ont tendance à rendre les choses compliquées sans raison, en ajoutant des modèles mentaux et des structures (agiles, Scrum, Kanban, etc.). Ce qui est important, c’est que peu importe le nombre de meetings ou de process que vous avez autour de la construction d’une application, tout peut se simplifier en ces quatre étapes.
Planning
Je pourrais citer des dizaines de citations sur le sujet, et il y a une bonne raison pour laquelle on a toujours un plan. Qu’on le suive ou non, c’est toujours mieux d’en avoir un.
Petit coup de pub, Ansearch aide énormément à cette étape (on est un outil d’intelligence client -customer intelligence-) qui automatise cette étape : on réduit les biais cognitifs, les erreurs et on organise les systèmes de ticket, pour que vous soyez sûr de construire ce dont vos clients ont besoin. Et aussi surprenant que ce soit, c’est très compliqué, beaucoup de gens et d’organisations mélangent ce que leurs clients veulent et ce que leur manager (ou leur voix intérieure) veut.
Documents produits et documentation technique
L’une des parties les plus difficiles de l’ingénierie réside dans la complexité que peuvent atteindre les systèmes. Aucun être humain n’est capable de se souvenir de chaque détail d’un logiciel, la documentation est donc primordiale. Les équipes d’ingénierie ont généralement des années d’avance sur le reste de l’entreprise sur ce sujet, tant c’est crucial.
Cela peut aller de simples fichiers texte (markdown) à des constructeurs de sites web avancés.
Le Markdown est un format de fichier optimisé pour la rapidité de rédaction (ce site est construit avec). Des symboles indiquent comment le texte doit être rendu (ex. # pour un titre, > pour une citation, ** ** ** pour mettre en gras, etc.).
Parmi les outils les plus utilisés dans ce domaine :

- Notion, Confluence, Coda, et Obsidian: ce sont principalement des éditeurs de texte, avec de nombreux usages, parfois en dehors du monde de l’ingénierie. Ils servent surtout à documenter les aspects non techniques (management, exigences produit, etc.).
-
Swagger, Postman, Redocly: Les documents Swagger/OpenAPI sont un standard; et Swagger (la compagnie) permet de les publier facilement. Ces documents ne sont généralement pas rédigés par des humains, mais générés automatiquement. Leur rôle est d’expliquer comment interagir avec un autre serveur via des contrats (« donne-moi cette donnée, je te renverrai autre chose »). Ces contrats s’appellent des API, pour Application Programming Interfaces (j’en parlerai dans un autre article).
-
Docusaurus et alternatives: ce sont de véritables sites web, parfois intégrés au produit principal vendu. Leur objectif est d’expliquer à d’autres ingénieurs comment utiliser ou interagir avec ce qui a été construit. Ils intègrent parfois Swagger directement, plutôt que d’avoir deux outils séparés. On les utilise uniquement lorsque la documentation est destinée à des personnes externes, car ils demandent bien plus d’investissement que les deux autres types.

Gestion des tâches
Les principaux outils utilisés sont Jira et Linear (et moins souvent GitHub projects).
Ce sont des systèmes de tickets (un ticket = une tâche à accomplir). Ces outils sont essentiels pour distribuer le travail d’une équipe et savoir qui fait quoi. Les tickets sont généralement la principale source d’information pour un ingénieur afin de comprendre ce qu’il doit faire et pourquoi. C’est donc important de les rédiger en détail.
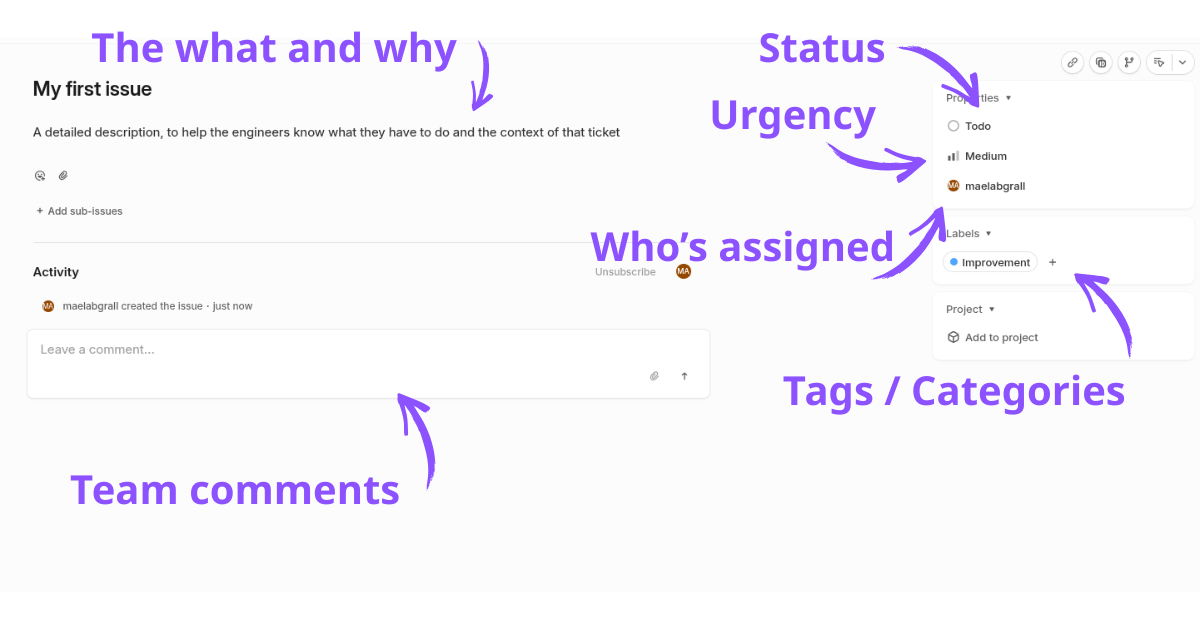
Les tickets ont des statuts, pour indiquer où en est le travail:
- Backlog pour les tickets sur lesquels on ne travaille pas actuellement, parce qu’ils ne sont pas urgents ou que l’équipe n’a pas le temps de les traiter. Un travail majeur de l’équipe est de maintenir ce backlog organisé et d’éviter qu’il n’explose. Trop de tâches = moral en berne et organisation plus difficile.
- Todos pour les tickets sur lesquels quelqu’un travaillera dès qu’un ingénieur sera disponible.
- In progress / In review: pour les tickets sur lesquels quelqu’un travaille activement, ou qui attendent qu’un autre ingénieur relise le travail.
- Done: la tâche est accomplie.
Interface & visuels
Les ingénieurs ont des niveaux très variables de “goût”. C’est pourquoi il est aussi très important de prévoir l’apparence d’une application, son comportement et la manière dont les utilisateurs interagiront avec elle.
Là encore, les outils utilisés dans cette partie de la boucle vont d’une simple feuille de papier à des outils très avancés. Nous allons nous concentrer sur deux seulement, car ce sont parmi les plus répandus dans l’industrie :

Figma: Figma est un outil pour créer des interfaces. Vous faites glisser et déposer du texte, des formes, des images, vous les organisez et créez des wireframes (des maquettes pour visualiser un design préliminaire) ou une interface entièrement aboutie.
V0: À l’origine, V0 est une IA pour construire des sites web, et elle reste performante pour ça. Cependant, cet outil est de plus en plus utilisé pour aider à construire des interfaces et le design. La principale différence avec Figma est que V0 produit du code fonctionnel, donc ce qui est créé avec V0 est beaucoup plus interactif et peut être entièrement copié-collé par les ingénieurs. Vous n’avez pas non plus besoin de savoir utiliser Figma pour créer des prototypes, ce qui rend le prototypage bien plus rapide.

Building
Place à la construction ! Les ingénieurs utilisent une multitude d’outils ; je vais donc me concentrer uniquement sur ceux qui sont toujours présents :
Éditeurs et console (CLI)
Les éditeurs de code aident considérablement les ingénieurs dans leur travail : ils transforment un simple texte en quelque chose d’interactif et intelligent.
Le code est constitué de mots. Les éditeurs affichent certains mots en couleur pour aider à comprendre ce qu’ils signifient et comment ils sont utilisés, ça crée une hiérarchie visuelle, très importante pour comprendre vite.
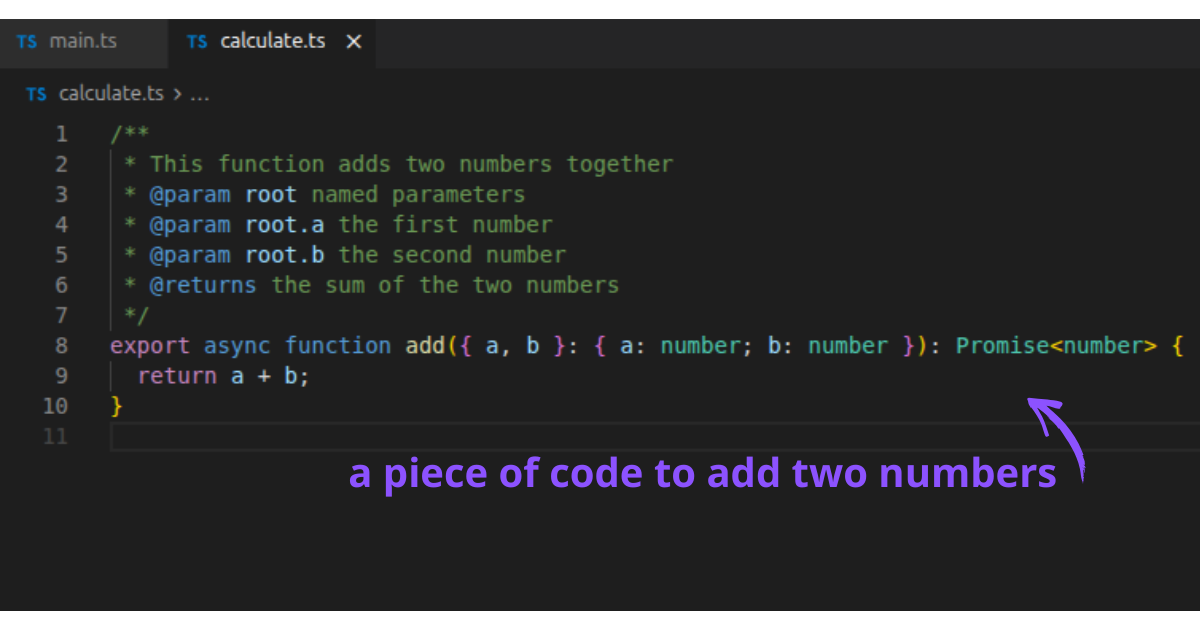
Le code est aussi très interconnecté, et les éditeurs aident les ingénieurs à voir ces liens facilement : si vous utilisez un morceau de code provenant d’un autre fichier, l’éditeur peut vous montrer d’où il vient et la documentation qui y est associée.
La console permet aux ingénieurs d’interagir avec le système en utilisant uniquement des mots. Elle est antérieure aux interfaces visuelles.
Les interfaces visuelles ont commencé à apparaître vers les années 70, et Apple a été le premier à les rendre vraiment grand public en 1983-1984. Soit 30 à 40 ans après les premiers ordinateurs numériques.
La ligne de commande est encore très utilisée aujourd’hui car elle est bien plus rapide (quand on sait s’en servir) que de devoir cliquer avec une souris. C’est la raison principale pour laquelle on l’utilise encore.
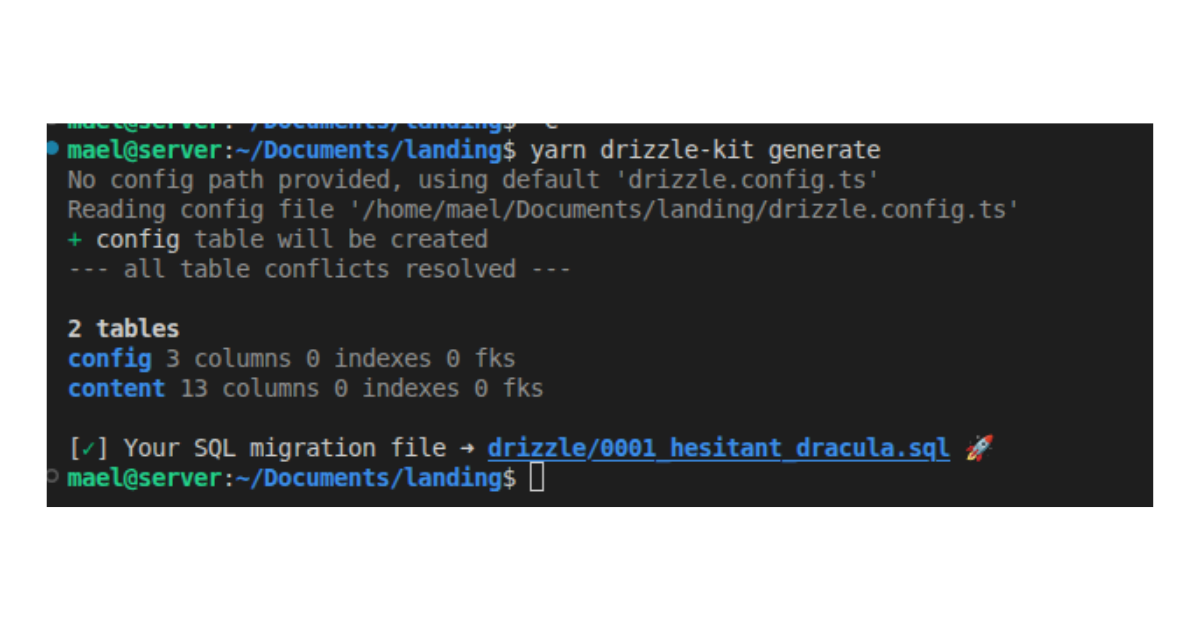
CLI (pour command line interface) est un programme conçu exclusivement pour être utilisé depuis la ligne de commande : il n’a pas d’interface visuelle. Dans cette capture d’écran, j’ai appelé un programme pour générer du code.
image of Vitest, from their documentation
Testing
Les bons ingénieurs testent toujours leur code. Ces tests sont pour la plupart automatisés et vont essayer toutes les combinaisons possibles d’utilisation de ce code.
Même si ce n’est pas immédiatement évident (si ça marche, pourquoi tester ?), les tests deviennent très importants pour éviter les bugs à l’avenir : lors de la maintenance, un test qui échoue indique que le comportement du code vient de changer. Quand vous avez des millions de lignes de code, c’est votre seul moyen de détecter quelque chose qui s’est cassé après une modification.
C’est essentiel pour l’assurance qualité (garantir que le logiciel maintient un haut niveau de qualité dans le temps).

Git & code repositories
Une fois le travail terminé, vous avez besoin d’un moyen de stocker le code. Git est un logiciel qui permet de faire ça (il a été inventé par la même personne qui a inventé Linux).
Le fonctionnement de Git est assez simple : vous avez des points de sauvegarde (appelés commits), des branches (une branche signifie que le code évolue dans un « espace de travail » séparé, sans interférer avec les autres branches), et un repository (un dossier à distance, où le code sera envoyé).
Les repositories sont l’endroit où le code est stocké. De nombreux services proposent des dépôts, les plus notables étant GitHub, GitLab et Bitbucket. Ces services intègrent également d’autres fonctionnalités utiles pour le déploiement du code.

Les branches sont ensuite fusionnées dans la « branche principale » (main branch), qui représente le code servi aux clients. Pour ce faire, les ingénieurs doivent créer une PR, ou Pull/Push Request (il n’y a pas de standard ici — vous « demandez » essentiellement à l’équipe de relire votre code et de le fusionner).
Reviews
Lorsqu’on travaille en équipe, une partie importante pour garantir la qualité est la revue de code : un autre ingénieur vient vérifier que le code respecte un certain standard (ce standard est directement lié au niveau de compétence de l’équipe ; une bonne équipe composée de juniors a toujours un standard plus élevé qu’une mauvaise équipe de seniors).
La ou les personnes effectuant la revue vont ajouter des commentaires et demander des améliorations, ou vont accepter la demande et fusionner ce code avec la branche principale.
C’est aussi un endroit où les ingénieurs peuvent être très durs entre eux. Il y a eu souvent du drama dans les reviews de projets open source, car (encore une fois) la qualité d’un projet est directement impactée par la qualité des vérifications.
Deploying / Déploiement
L’étape suivante du cycle d’ingénierie est de déployer ce code. Il existe plusieurs façons de le déployer :
- Sous forme d’application (difficile, lent)
- Sous forme d’application web (instantané, très facile)
- Sous forme de serveur (instantané, facile)
Malheureusement, dans la plupart des cas, vous ne choisissez pas où déployer : si vos clients veulent une application mobile, vous devrez déployer une application mobile.
Cependant, il vaut mieux avoir autant de logique que possible dans une application web ou un serveur, pour réduire les problèmes liés aux applications classiques.
Avant d’entrer dans les détails du déploiement, il est important de noter que dans les grandes équipes, c’est généralement le travail d’ingénieurs dédiés, car cela peut devenir complexe très rapidement.
Native app
Il s’agit d’une application qui doit être téléchargée sur un appareil (ordinateur, téléphone, ou électronique embarquée). On les appelle applications natives.
L’avantage des applications est qu’elles peuvent fonctionner entièrement hors ligne (par exemple : votre calculatrice). Le principal inconvénient des applications est que leur déploiement est difficile et ne peut pas être rétrogradé (une fois publié, c’est publié).
Il y a deux grandes difficultés:
- Chaque appareil a une configuration différente (c’est moins le cas pour les apps iOS et Mac), donc ce qui fonctionne avec l’ordinateur A ou votre téléphone risque de ne pas fonctionner avec un autre.
- Chaque utilisateur a son propre rythme de mise à jour. Le pire est les applications Windows classiques (différentes des applications du Windows Store), où les gens les mettent à jour quand ils veulent. Votre application (si elle fonctionne en ligne) doit donc être capable de fonctionner avec la nouvelle version, l’ancienne, et parfois une version vieille de plusieurs mois (Jim n’a pas voulu mettre à jour l’appli ; Jim utilise toujours Windows Vista en 2026).
Les applications natives sont distribuées sur :
- L’App Store pour iOS
- Le Windows Store ou par téléchargement direct sur Windows.
- Various stores on Android, mainly the Play Store.
- Une multitude de stores sur Linux (c’est d’ailleurs de là que vient le concept de « store »).
- Aucune idée pour Mac, je hais Mac.
L’application web et l’application web progressive
Avec l’apparition de navigateurs web puissants, une nouvelle façon de construire des applications est née : l’application web. Ce sont des applications qui vivent entièrement dans votre navigateur. Google Documents en est un bon exemple.
Les applications web sont très faciles à mettre à jour : chaque fois qu’un utilisateur se rend sur votre site, il obtient la dernière version de l’application. Vous avez fait une erreur ? Vous pouvez la corriger en quelques secondes.
L’inconvénient des applications web est qu’elles n’ont pas autant de capacités que les applications natives, ou sont moins performantes (par exemple, même si vous pouvez faire tourner un jeu vidéo dans le navigateur, ce ne sera pas aussi bien que de le faire tourner directement sur votre ordinateur).
Les applications web progressives (Progressive Web Apps) sont un type spécifique d’applications web qui tentent de combler le fossé entre une application native et une application web, en permettant notamment un fonctionnement hors ligne (toujours dans le navigateur, mais fonctionne même sans connexion Internet) ou, sur Android, l’installation de l’application web comme une application normale (vous obtenez une icône comme les applications natives, sans passer par un store). Cependant, les utilisateurs mobiles ne comprennent pas bien les applications web progressives.
Les applications web sont également appelées frontend par les ingénieurs.
Pour distribuer des applications web, vous pouvez soit les intégrer à votre serveur, soit utiliser des services dédiés. Ces services sont les mêmes que pour les serveurs.

Les serveurs
Les applications natives et les applications web font face à un même problème : les appareils ont une capacité de stockage et de puissance de traitement limitée. Il est également fastidieux de transférer vos données d’un appareil à un autre.
Les serveurs vous permettent d’avoir un stockage et une puissance de traitement virtuellement illimités. Ils vous permettent aussi d’accéder à vos données depuis plusieurs appareils (ex : lire vos e-mails depuis votre bureau, puis les consulter depuis votre téléphone).
Ils sont relativement faciles à déployer et à mettre à jour, et comme les applications web, il est possible de revenir en arrière en cas de problème de déploiement.
Le code des serveurs est appelé backend par les ingénieurs.
Pour déployer du code sur des serveurs, vous avez plusieurs options :
- Sur le cloud public : ce sont des entreprises dédiées à vous fournir des ordinateurs. Vous louez des machines à l’heure, et en échange vous n’avez rien à gérer. C’est l’option la plus simple et la plus sécurisée, car votre équipe n’est pas responsable de la mise à jour et de la sécurisation du serveur.
- Sur le « cloud privé » : c’est la même chose que le cloud public, mais dans une logique purement B2B. Cela signifie qu’au lieu d’être votre cloud, le serveur vivra dans le cloud de votre client. C’est plus impliqué que le cloud public, mais peut les rassurer en matière de confidentialité, car ils ont plus de contrôle sur ce qui se passe.
- On-premises / on metal / Self-hosted (le plus détesté, car c’est plus difficile qu’une application native). À éviter comme la peste, quiconque utilise encore cela en 2026 est dans le déni et a de sérieux manques techniques. It’s less secure than any other option, and very tedious. C’est moins sécurisé que toute autre option, et très fastidieux. La seule exception est pour les ingénieurs qui construisent leurs propres applications et en sont les seuls utilisateurs. Je vais expliquer plus en détail pourquoi dans un autre blog sur “build vs buy”, la version courte, vous ne voulez pas manager ça, et personne ne devrait avoir à le faire.
Les plus grandes entreprises de cloud sont Amazon (avec Amazon Web Services ou AWS), Microsoft (avec Azure) et Google (avec Google Cloud ou GCP). Des entreprises dédiées à la location de serveurs existent, mais sont beaucoup plus petites et régionales. Choisir ces acteurs plus petits est un risque, car recruter quelqu’un qui connaît ces plateformes est rare, et elles sont généralement plus complexes à utiliser que les trois grands cités ci-dessus
Certains concurrents sont de plus en plus utilisés, car ils proposent une plateforme encore plus simple que les grands clouds : Vercel et Cloudflare. Ils ont cependant une offre plus restreinte, ou, dans le cas de Vercel, une facture plus élevée.

CICD (Intégration continue, Déploiement continu)
Pour déployer les applications, les ingénieurs ont mis en place des pipelines, afin d’automatiser le processus autant que possible.
Cela signifie que dès que le code est mis à jour dans le repository, les applications sont automatiquement déployées.
DevOps and DevSecOps
Les ingénieurs qui travaillent sur les pipelines CI/CD et les déploiements s’appellent des ingénieurs DevOps et DevSecOps. Leur mission est de s’assurer que les pipelines sont rapides et que le déploiement fonctionne comme prévu.
Ils veillent également à ce que le code soit déployé de manière sécurisée, et prennent parfois en charge la prochaine grande étape de la boucle d’ingénierie : la surveillance des applications.
Ces ingénieurs sont rares dans les petites entreprises, ou n’interviennent qu’en tant que consultants, car ils ne sont nécessaires que lorsque le déploiement ou la surveillance des applications devient complexe. Les deux plateformes citées plus haut (Vercel et Cloudflare) se sont construites autour de l’idée de ne pas avoir à recruter ou de savoir faire du DevOps: n’importe quel ingénieur peut se servir de ces plateformes très facilement.

Monitoring
La dernière étape de la boucle d’ingénierie est de surveiller l’application (monitor).
Il y a trois raisons de le faire :
- Détecter les bugs qui surviennent chez les utilisateurs
- S’assurer que les ressources sont utilisées correctement (éviter de louer trop de serveurs ou pas assez)
- Comprendre comment le produit est utilisé (les utilisateurs sont-ils satisfaits, comprennent-ils l’application, etc.), ainsi qu’à des fins marketing (comprendre comment les gens ont découvert l’application, combien de temps ils passent sur une page spécifique, etc.).
Pour détecter les bugs, l’outil le plus couramment utilisé s’appelle Sentry: lorsqu’un bug survient, Sentry stocke autant d’informations que possible sur ce qui s’est produit, et notifie les ingénieurs.
Pour vérifier l’utilisation de ressources, beaucoup d’outils existent, le plus connu étant Datadog.
Pour le produit et le marketing, de nombreux outils sont disponibles: Posthog, Mixpanel, Hotjar, Segment, etc. Ces outils sont appelés outils d’analyse (analytics tools).
Google Analytics est l’un de ces outils, mais il est important de noter que sa configuration par défaut n’est pas conforme au RGPD.
Les informations recueillies dans ces outils sont importantes lorsqu’on revient au début de la boucle : elles aident à prendre des décisions éclairées lors de la planification.
C’est tout pour aujourd’hui!
Mon équipe et moi allons continuer de publier à propos de la tech, quelques blogs qui sont prévus incluent “build vs buy vs partner vs simplement dire non”, les types de stockages et comment les utiliser au mieux, les wrappers, frameworks, librairies, APIs, MCP et l’open source.
Si vous avez envie de voir un blog ou un thème particulier, n’hésitez pas à envoyer un email à contact@ansearch.ai
– Mael